
type
status
date
slug
summary
tags
category
icon
password
前言
之前在前面的文章里已经介绍了前期的一些工作流程,但是还有一些没弄明白的地方,比如yolov5训练集、验证集、测试集之间的区别是什么。
正文
这部分详细介绍目前存在的疑惑。
训练集和验证集
非常感谢给我解答困惑的博主:梅花14的文章,标题为:训练集、验证集、测试集的区别,这次你一定能看懂。
训练集和验证集都是在训练阶段使用的!!!
也就是说,训练集和验证集是用于在训练阶段的测试,在我第一次训练的时候,忽视了这个细节的,没有对测试集进行数据标注。
过度拟合
过度拟合是指模型在训练数据上表现良好,但在未见过的测试数据上表现较差的情况。为了避免模型的过度拟合,可以采取以下几种方法:
- 数据集扩充(Data Augmentation):通过对训练数据进行随机变换和增强,可以增加数据的多样性,从而减少过度拟合的风险。例如,在图像分类任务中,可以进行随机裁剪、旋转、缩放、翻转等操作来生成更多的训练样本。
- 正则化(Regularization):正则化是通过在模型的损失函数中引入额外的惩罚项来减少模型复杂度,从而降低过度拟合的风险。常见的正则化方法包括L1正则化和L2正则化。L1正则化通过对模型参数的绝对值进行惩罚,可以促使模型参数稀疏化;L2正则化通过对模型参数的平方进行惩罚,可以防止参数过大。
- 早停(Early Stopping):早停是指在训练过程中监控模型在验证集上的性能,并在性能不再提升时停止训练,以避免过度拟合。通过早停,可以在模型开始过拟合之前停止训练,从而得到泛化能力更好的模型。
- Dropout:Dropout是一种在训练过程中随机将部分神经元的输出置为零的操作。通过随机丢弃神经元,可以减少神经网络的复杂性,从而降低过度拟合的风险。
- 模型复杂度控制:过度复杂的模型更容易过拟合,因此可以通过减少模型的层数、隐藏单元的数量或特征的维度等方式来控制模型的复杂度。
- 交叉验证(Cross-Validation):交叉验证可以用于评估模型的性能并选择合适的超参数。通过将数据集分为训练集和验证集,并多次进行训练和验证,可以更准确地估计模型的泛化能力。
- 获取更多数据:增加训练数据量是减少过度拟合的有效方法。更多的数据可以提供更多的样本和场景,有助于模型学习更一般化的特征。
综合使用上述方法可以帮助减少模型的过度拟合风险。需要根据具体问题和数据集的特点选择适合的方法,并进行实验和调优以获得最佳结果。
评估yolov5模型性能指标
在使用YOLOv5或其他目标检测模型时,可以使用以下指标来评估模型的性能:
- 平均精度均值(mAP):mAP是目标检测任务中常用的评估指标之一。它综合考虑了模型在不同类别上的精度和召回率,并计算出一个综合的平均值。通常,mAP值越高,表示模型在目标检测任务上的性能越好。
- 精度(Precision)和召回率(Recall):精度是指模型预测为正的样本中实际为正的比例,召回率是指实际为正的样本中被模型预测为正的比例。在目标检测任务中,可以根据不同的阈值来计算精度和召回率,并绘制精度-召回率曲线。通常,我们希望模型能够在高精度和高召回率之间取得平衡。
- 漏检率(False Negative Rate)和虚警率(False Positive Rate):漏检率是指实际为正的样本中被模型错误地预测为负的比例,虚警率是指实际为负的样本中被模型错误地预测为正的比例。在目标检测任务中,我们希望漏检率和虚警率都尽可能地低。
- 定位误差(Localization Error):定位误差是指模型在预测目标位置时与真实位置之间的差距。通常,可以使用平均定位误差(Mean Localization Error)来评估模型的目标定位准确性。
这些指标可以通过在测试集上进行推理和评估来计算。YOLOv5提供了用于计算mAP和其他指标的评估脚本,可以使用这些脚本来评估模型的性能。此外,还可以可视化模型的预测结果,检查模型在不同类别上的表现,并进行定性评估。
需要注意的是,评估模型性能时应该使用独立于训练集和验证集的测试集数据,以确保评估结果的客观性和准确性。
模型拐点
在机器学习中,模型的拐点通常指的是学习曲线上的拐点。学习曲线是一种图形,用于显示模型在训练集和验证集上的性能随着训练样本数量或训练迭代次数的变化情况。
在学习曲线中,通常会有两条曲线:一条表示模型在训练集上的性能,另一条表示模型在验证集上的性能。随着训练样本数量的增加或训练迭代次数的增加,这两条曲线的性能会发生变化。
模型的拐点指的是学习曲线上的一个转折点或拐点,通常是指验证集上的性能开始出现下降或趋于稳定的点。在这个点之前,模型可能还在学习和改进,性能会随着训练的进行而提高;而在这个点之后,模型可能已经过拟合了,继续训练可能不会带来更好的性能。
找到模型的拐点可以有助于确定合适的训练迭代次数或训练样本数量。当模型的性能在验证集上达到最佳水平时,可以停止训练,以避免过度拟合。此时,模型的泛化能力可能最好,可以在未见过的数据上表现良好。
需要注意的是,模型的拐点并非绝对的,可能因数据集、模型复杂度和任务特点等因素而有所不同。因此,在实际应用中,需要根据具体情况和实验结果来判断模型的拐点,并进行适当的调整和优化。
寻找模型的拐点
寻找模型的拐点通常需要观察学习曲线并进行分析。以下是一些方法可以帮助你找到模型的拐点:
- 绘制学习曲线:在训练过程中,记录模型在训练集和验证集上的性能指标,如损失函数、准确率、mAP等。然后,将这些指标随着训练样本数量或训练迭代次数的变化绘制成学习曲线。
- 观察验证集性能:关注模型在验证集上的性能指标,如验证集上的准确率、mAP等。观察性能是否开始下降或趋于稳定。一般来说,当验证集性能开始下降或趋于平稳时,可能表示模型的拐点。
- 比较训练集和验证集性能:观察模型在训练集和验证集上的性能差异。如果模型在训练集上的性能远远好于验证集,可能表示模型已经过拟合,继续训练可能不会带来更好的性能。这时可以考虑找到一个合适的拐点停止训练。
- 使用早停法(Early Stopping):早停法是一种常用的寻找模型拐点的方法。它基于验证集性能的变化,在验证集性能连续一定次数没有提升时,停止训练并选择此时的模型作为最终模型。这可以避免过度拟合,并找到一个在验证集上性能最佳的模型。
- 交叉验证:使用交叉验证可以更准确地评估模型的性能,并找到模型的拐点。通过将数据集分成多个折(folds),每次使用不同的折作为验证集,其他折作为训练集,进行多次训练和验证,可以得到更稳定的学习曲线和更可靠的拐点估计。
需要注意的是,寻找模型的拐点并不是一个确定性的任务,而是需要结合领域知识和实验结果进行判断。同时,不同的任务和数据集可能会有不同的拐点位置和特点,因此需要根据具体情况进行分析和调整。
图形化理解
这部分首先要特别感谢up主:yolo目标检测的文章:目标检测之性能指标













首先是关于混淆矩阵的理解,用于理解准确率,召回率
这张图更加形象地解释了什么是准确率和召回率
这张图介绍了AP和mAP的含义,mAP是取所有类别的平均值。
这张图我猜测应该是mAP的COCO标准
这种图是介绍预测框和绘制框重叠率
这张图用直观的方式介绍了什么是重叠率
根据不同的重叠率对应的宽松程度
比较同一数据集不同模型的性能
AP计算的11点法,在2010前适用
AP计算之积分法
总结AP计算方法的变化
还有一些其他的性能指标来对模型进行评价
寻找拐点
现在我感觉对训练多少轮模型是最佳的状态还没能有一个非常好的评估,我也只能通过观察,不同轮数准确率的变化来猜测拐点。当然炼丹太消耗时间和精力了。我跑300轮就得花费两个多小时,100轮差不多也得半个多小时。但是100轮的模型的精准度似乎比300轮的准确度还要高出0.002,应该是出现了拐点。然后我现在在等130轮的训练结果。
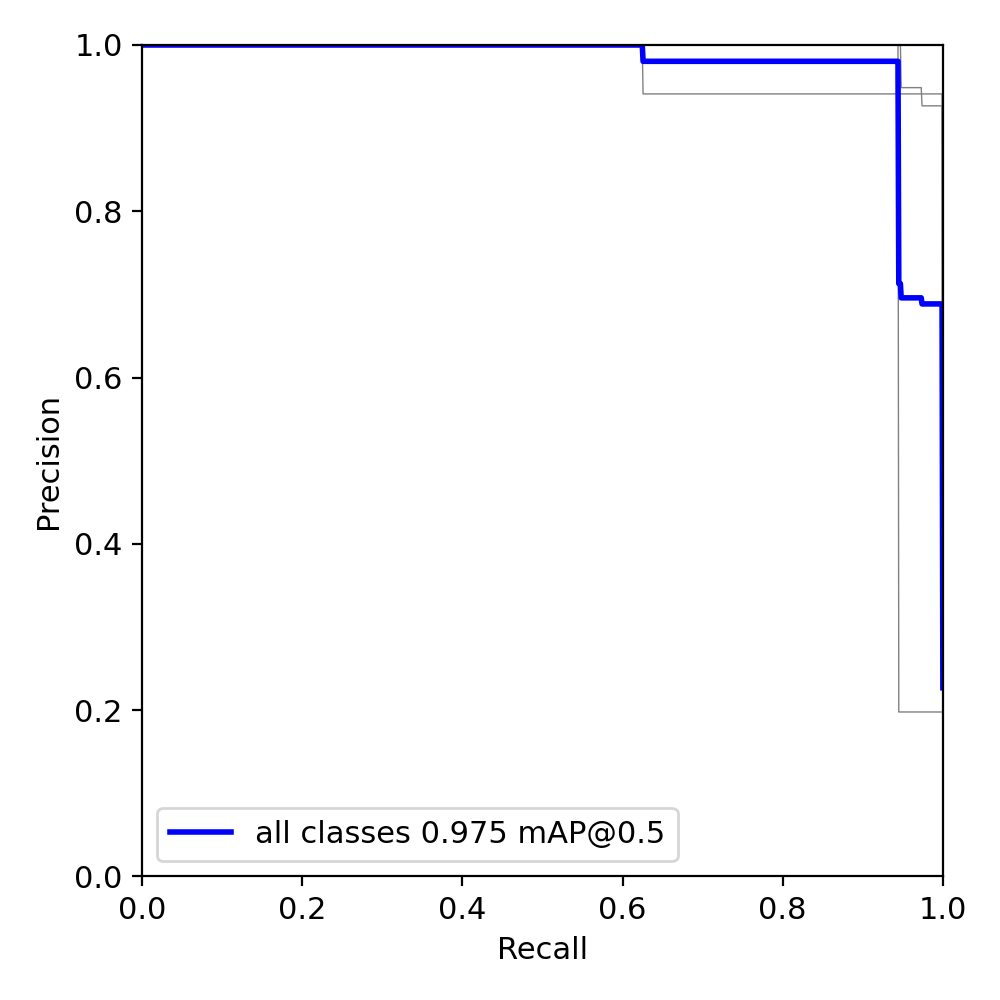
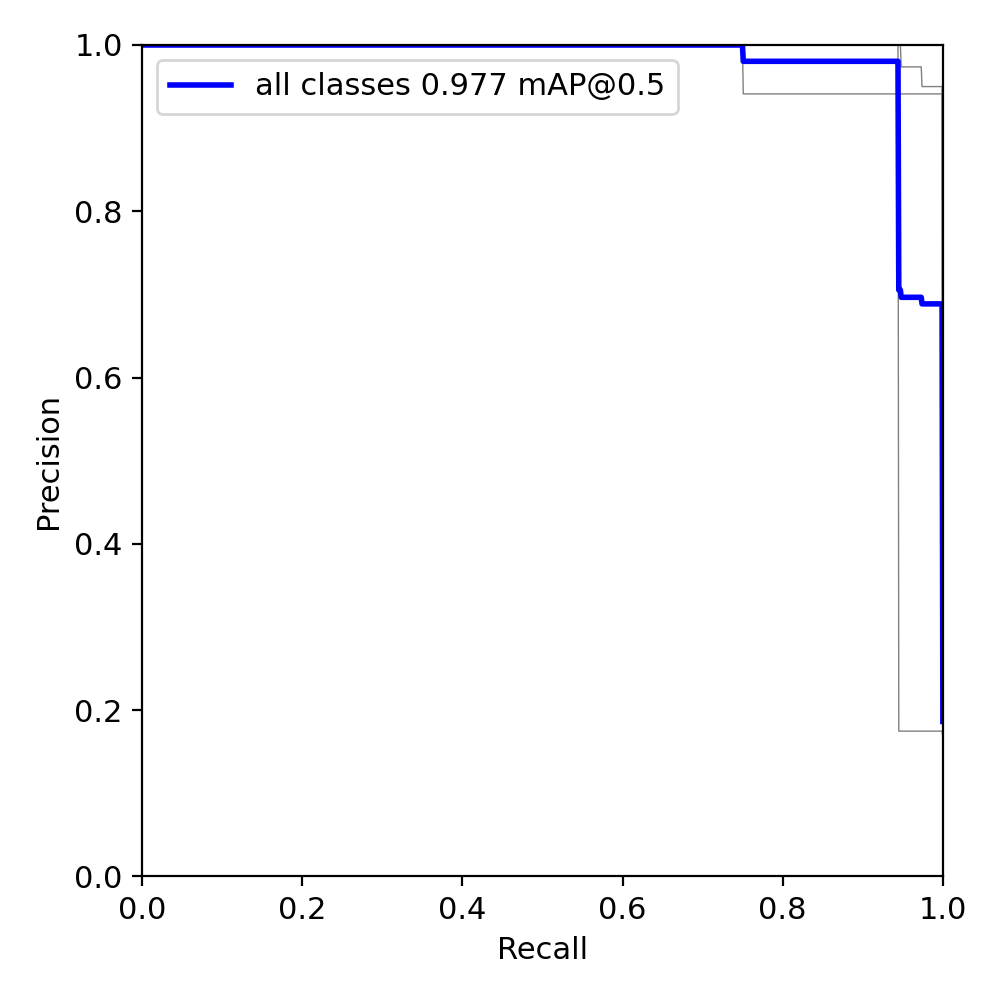
总结
接下来的主要任务是把中期的课设报告继续完善一下,提升逻辑性,美观度。
- 特别是前期的方案对比,我觉得可以继续搜集一些资料,使得其更加饱满一些
- 然后对于yolov5原理这部分还需要继续优化
- 后面对于模型的评估指标,包括自己思考和遇到的一些问题也可以持续优化。
- Author:非常6+1
- URL:https://matrixcore.love/article/yolov5-2
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!